Dans le monde du Big Data et de la recherche d’information, la rapidité d’accès aux données est devenue un enjeu crucial. Imaginez devoir parcourir des centaines milliers de CV au format PDF, ligne par ligne, pour trouver un profil correspondant à vos critères (ex: avoir le keyword “java”). C’est exactement ce que représente une recherche séquentielle dans une base de données classique. Heureusement, Elasticsearch nous offre une solution bien plus élégante grâce à ses index inversés.
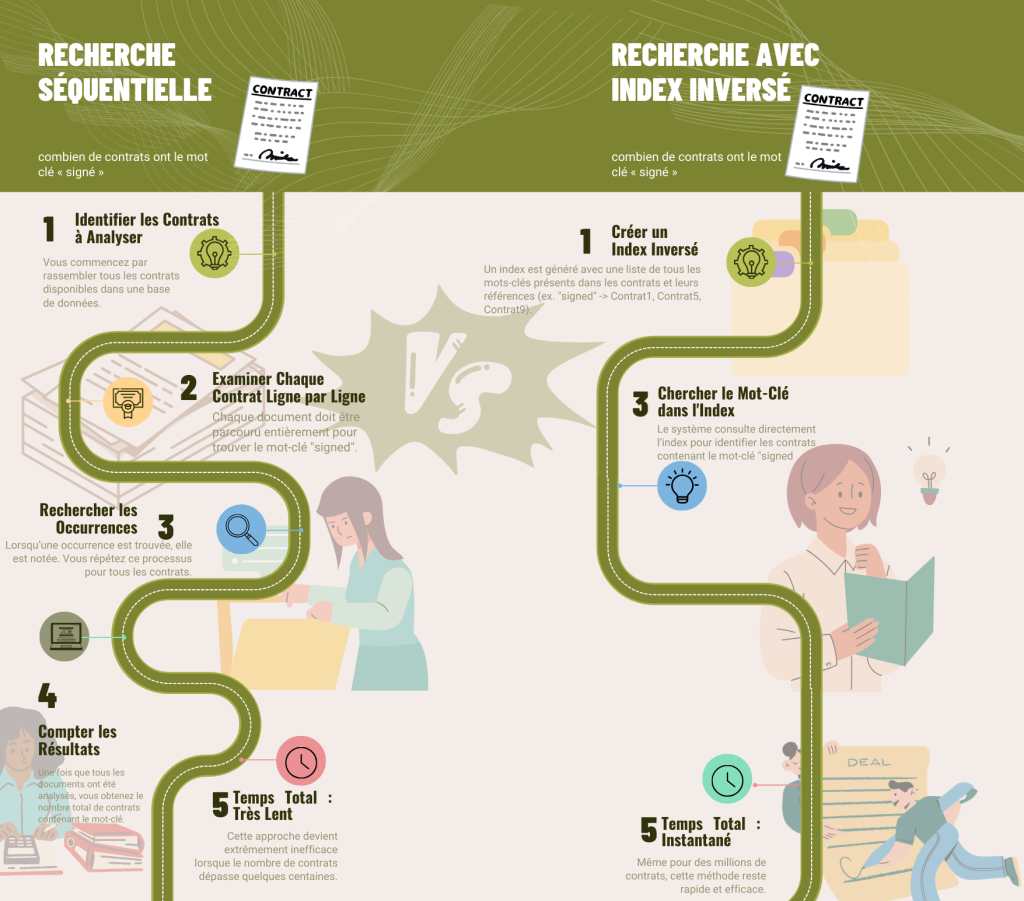
La recherche séquentielle : L’approche naïve
Commençons par comprendre ce qu’est une recherche séquentielle. Lorsque vous cherchez le mot « innovation » dans une base de données traditionnelle, le système doit parcourir chaque document, ligne par ligne, pour trouver les occurrences de ce terme. Si vous avez 1 million de documents, le système devra potentiellement examiner chacun d’entre eux. La complexité temporelle est donc O(n), où n est le nombre total de documents. Pour mettre cela en perspective, si chaque document prend 1 milliseconde à être analysé, la recherche dans 1 million de documents prendrait environ 16 minutes !
L’index inversé : Le secret de la performance d’Elasticsearch
Elasticsearch utilise une structure de données appelée index inversé, qui fonctionne de manière similaire à l’index que l’on trouve à la fin d’un livre. Au lieu de stocker les documents avec leur contenu, l’index inversé maintient une liste de tous les termes uniques, et pour chaque terme, garde une référence vers tous les documents qui le contiennent.
Prenons un exemple concret. Supposons que nous ayons trois documents :
- « L’innovation technologique transforme les entreprises »
- « Les entreprises adoptent l’intelligence artificielle »
- « L’innovation stimule la croissance économique »
L’index inversé ressemblerait à ceci :
- innovation -> Doc1, Doc3
- technologique -> Doc1
- entreprises -> Doc1, Doc2
- intelligence -> Doc2
- artificielle -> Doc2
- stimule -> Doc3
- croissance -> Doc3
- économique -> Doc3
La différence de performance en chiffres
La différence de performance entre ces deux approches est spectaculaire. Prenons quelques métriques concrètes basées sur des tests réels :
Pour une base de données d’un million de documents, avec une recherche du terme « innovation » :
- Recherche séquentielle : ~16 minutes
- Recherche avec index inversé : < 100 millisecondes
Cette différence s’accentue de manière exponentiellement avec la taille de la base de données. C’est pourquoi Elasticsearch peut gérer des recherches complexes sur des téraoctets de données en temps quasi réel.
Au-delà de la simple recherche ELASTICSEARCH
L’efficacité des index inversés ne se limite pas à la simple recherche de mots-clés. Elasticsearch enrichit cette structure avec des fonctionnalités supplémentaires :
- Analyse linguistique : Les termes sont normalisés (suppression des accents, mise en minuscules) et peuvent être réduits à leur racine (stemming).
- Pertinence des résultats : Chaque correspondance est associée à un score qui prend en compte divers facteurs comme la fréquence du terme (TF-IDF).
- Recherche approximative : Même avec des fautes de frappe, Elasticsearch peut trouver les documents pertinents grâce à des algorithmes de distance d’édition.
Comment optimiser vos index inversés
Pour tirer le meilleur parti des index inversés d’Elasticsearch, voici quelques bonnes pratiques :
Premièrement, réfléchissez bien à votre mapping. Un mapping approprié peut significativement améliorer les performances de recherche. Par exemple, pour un champ qui ne nécessite pas de recherche full-text, définissez-le comme ‘keyword’ plutôt que ‘text’.
Deuxièmement, utilisez des analyzers adaptés à votre cas d’usage. Si vous travaillez avec du texte en français, l’analyzer ‘french’ prendra en compte les spécificités de la langue comme les articles et les conjugaisons.
Enfin, pensez à la segmentation de vos index. Des index plus petits et bien organisés permettront des recherches plus rapides. Une pratique courante consiste à segmenter les index par période pour les données temporelles.
Conclusion
La puissance d’Elasticsearch réside dans sa capacité à transformer une tâche qui serait autrement impossible (rechercher dans des millions de documents en temps réel) en une opération quotidienne simple. Les index inversés ne sont qu’une partie de ce qui rend Elasticsearch si performant, mais ils en constituent certainement le fondement le plus important.
La prochaine fois que vous effectuerez une recherche instantanée dans des millions de documents, vous saurez que c’est grâce à cette structure de données ingénieuse qui transforme le parcours séquentiel fastidieux en un saut direct vers l’information pertinente.